Qualche giorno fa ho pubblicato un articolo in cui faccio una personale riflessione sulle aree alluvionabili in Italia; le analisi effettuate sono state possibili grazie ai dati ISTAT e MiTE. Con questo articolo voglio parlarvi delle problematiche che ho incontrato nell'analisi di quei dati.
Partiamo dal cosa: per portare a termine il compito che mi sono dato ho dovuto usare Python, SQL e QGIS. Avrei voluto usare solo QGIS ma a parte i soliti problemi topologici mi sono imbattuto anche in altre grane.
Problema 1
I dati sul censimento suddivisi per Regione e scaricabili dal sito dell'ISTAT risultano essere non omogenei dal punto di vista dell'encoding. Questa è stata una rottura di scatole non da poco perchè usando Pandas avrei voluto concatenare semplicemente tutti i dati censuari suddivisi per Regione in un unico DataFrame. Cercando in giro ed inventandomi un po' di cose sono riuscito nell'intento comunque. Ho una domanda(chissà se riceverà risposta): perchè le 20 regioni hanno usato 3 distinti encoding?
with open(csv, 'rb') as rawdata:
result = chardet.detect(rawdata.read(10000))
if result['encoding'] == 'ascii':
result['encoding'] = 'latin1'
if target:
df = pd.read_csv(csv, encoding=result['encoding'], sep=';')
Ho preso spunto da questo articolo per questa parte di codice. Lo script legge 10.000 righe dal csv cercando di definirne l'encoding ed assegnando una certa probabilità al risultato finale. Ovviamente più è alta la probabilità più c'è certezza che l'encoding sia effettivamente quello indicato in result['encoding'] ma ho dovuto essere un po' creativo per riuscire a gestire tutte e tre le codifiche trovate in quei file.
Fatto questo ho potuto riversare tutto in un unico DataFrame esportabile in Excel all'occorrenza:
def __census_data(
input_data: Union[str, pathlib.PosixPath],
year: int = 2011,
ref_column: str = "P1",
output_data_folder: Union[str, pathlib.PosixPath] = None,
) -> None:
census_data_folder = input_data / f"census{year}" / 'data' / 'Sezioni di Censimento'
print("- List files ...")
files = tqdm(list_files_folders(path=census_data_folder, file_extension='.csv', type_on='files', subfolder=False))
census_array = []
for file in files:
# Convert str to path
csv = Path(file)
# Select only census data
target = re.findall("R", file)
# Look at the first ten thousand bytes to guess the character encoding
with open(csv, 'rb') as rawdata:
result = chardet.detect(rawdata.read(10000))
if result['encoding'] == 'ascii':
result['encoding'] = 'latin1'
if target:
# Extract only useful columns and put all into a DataFrame
df = pd.read_csv(csv, encoding=result['encoding'], sep=';')
data_columns = [
"CODREG", "REGIONE", "CODPRO", "PROVINCIA",
"CODCOM", "COMUNE", "PROCOM", "SEZ2011",
"NSEZ", ref_column,
]
data = df[data_columns]
data.rename(columns={ref_column: "target"}, inplace=True)
files.set_description("processing %s" % file)
census_array.append(data)
print("- List files | DONE ...")
# Create census DataFrame
print("- Create DataFrame ...")
census = pd.concat(census_array)
print("- Create DataFrame | DONE ...")
if output_data_folder is None:
return census
else:
file_name = f'census_data{year}.xlsx'
census.to_excel(output_data_folder / file_name, sheet_name=str(year))
print("- DataFrame saved as %s." file_name)
Ero interessato alla sola colonna della popolazione totale per cella censuaria, da cui la selezione della sola P1.
Problema 2
Errori topologici a morire! Sia lato ISTAT che MiTE! Ad esempio questo è quello che viene fuori facendo un check direttamente sul WFS del MiTE:
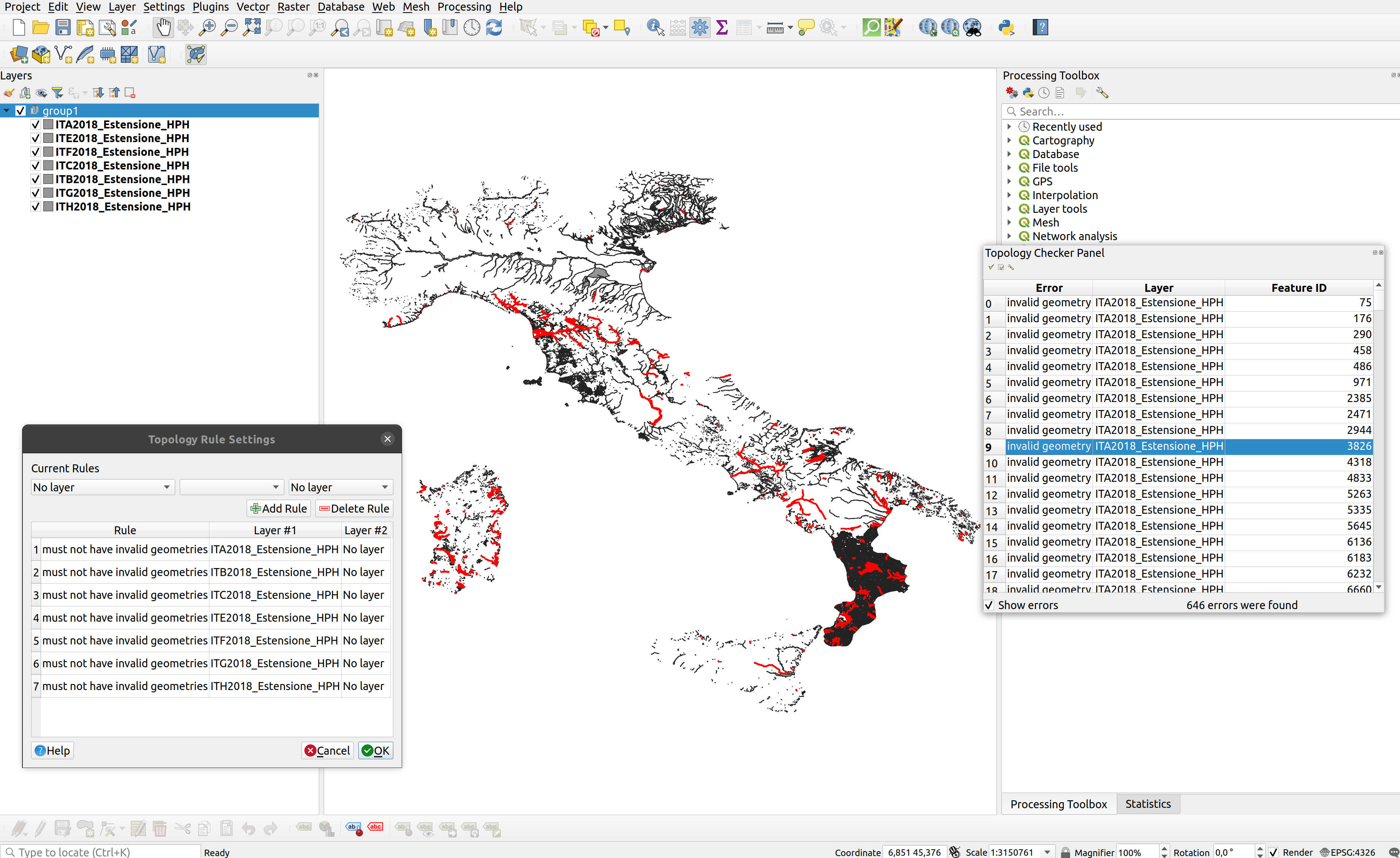
Gli errori sono quelli in rosso, per un totale di 646. Non ti nascondo che alcuni poligoni erano inservibili e li ho dovuti cestinare; come quelli che fanno riferimento all'area occidentale della Sardegna nella zona di Terralba.
Fortuna che già in passato ho affrontato questa problematica. Non è per niente difficile fare un check topologico, se fosse fatto a monte all'operatore che crea/carica i dati andrebbe via 1 minuto, cronometrato; e con un altro minuto si correggerebbero gli eventuali errori. Questi 2 minuti, massimo, spesi prima di mettere online i dati ne salvano svariati a noi poveri fruitori che pensiamo sempre che i dati siano corretti, puliti, come li produciamo noi; ma che solo dopo vari tentativi di analisi senza risultato ci accorgiamo che il problema che riscontriamo non lo abbiamo creato noi ma sta nei dati di base. E' possibile inserire nei capitolati di appalto e nei regolamenti interni della PA che i dati devono essere preventivamente puliti e normalizzati prima di metterli a disposizione dell'utenza?
Altra cosa: ma perchè in questi dati del 2018 c'è un buco su Trentino-Alto Adige e Marche? E perchè la Calabria ha quella elevatissima densità di dati? Mi sembra che in quel caso siano stati buttati dentro tutti i reticoli idrografici calabri e non solo le aree a rischio.
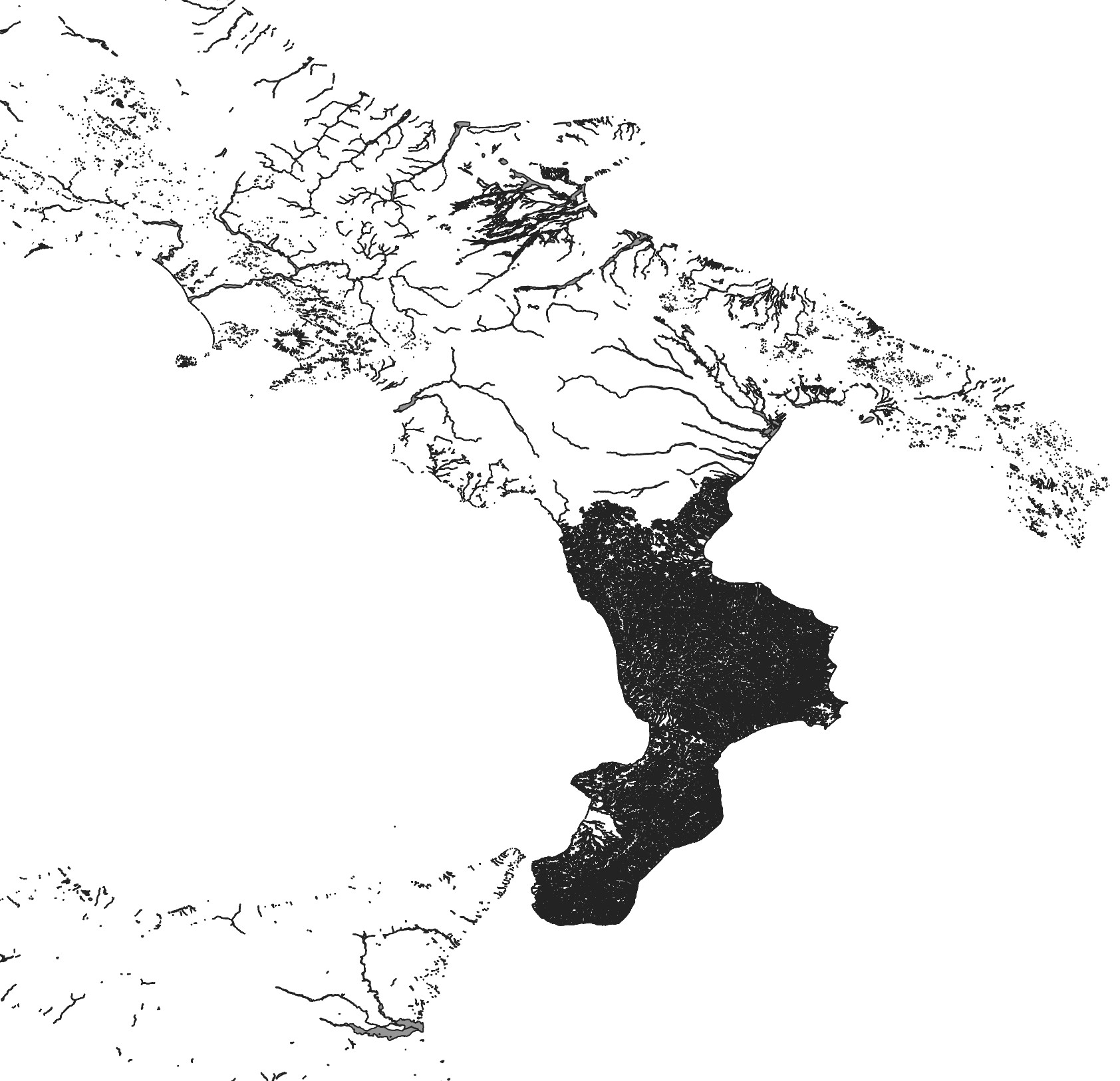
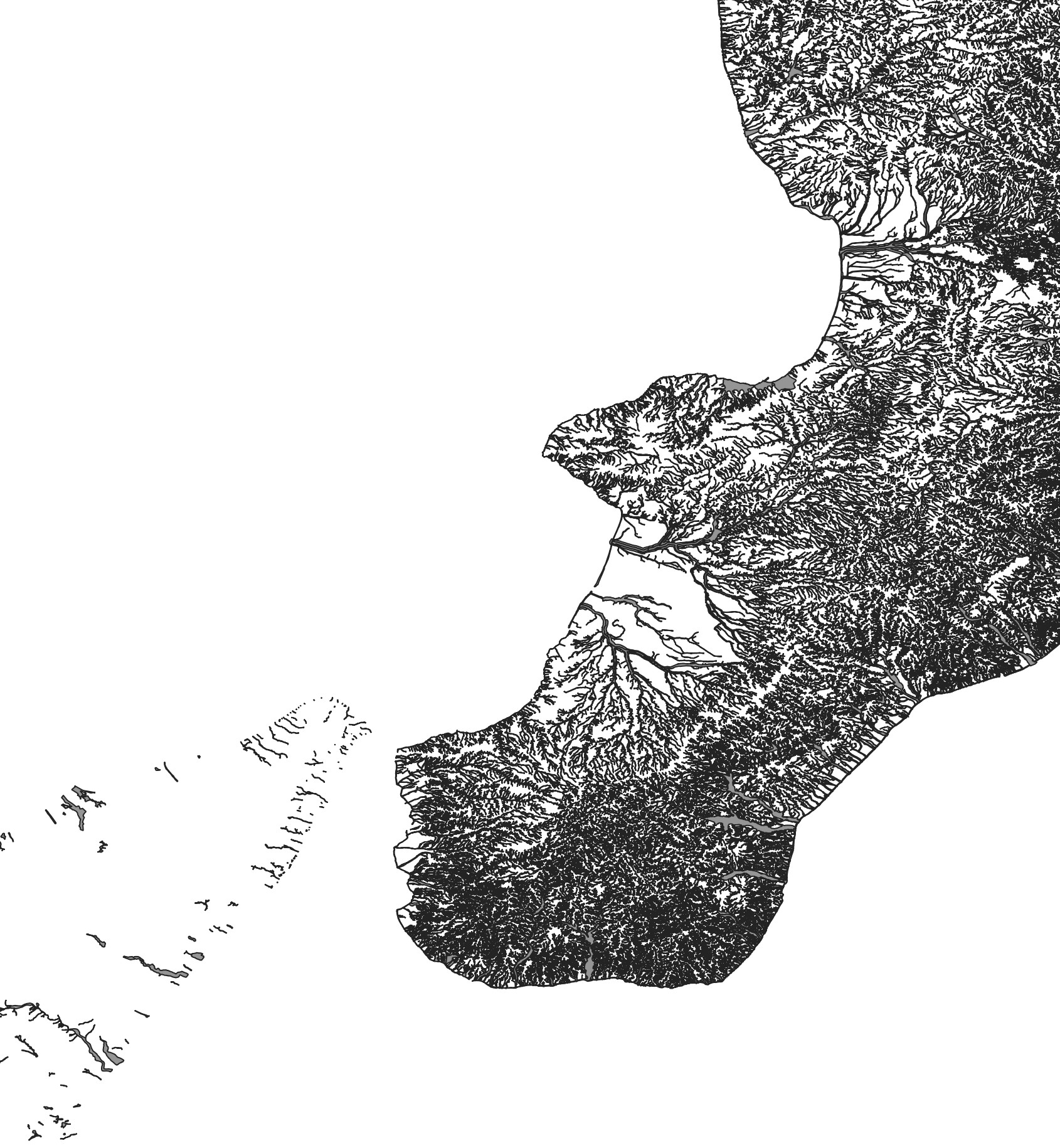
Tornando ai dati ISTAT, dopo la correzione topologica sono riuscito ad associare la popolazione per cella censuaria al relativo poligono:
def census_merge(
input_data: Union[str, pathlib.PosixPath],
year: int = 2011,
ref_column: str = "P1",
output_data_folder: Union[str, pathlib.PosixPath] = None,
) -> None:
# Get Census data
census_data = __census_data(input_data, year, ref_column)
# Get census geodata
census_geodata = __census_geodata(input_data, year)
# Create GeoDataFrame
print("- Make Geodataframe with requested census data ...")
census = gpd.GeoDataFrame(pd.merge(left=census_geodata, right=census_data, on='SEZ2011', how='left'), crs='EPSG:32632')
dropped_columns = [
"CODREG", "REGIONE", "CODPRO", "PROVINCIA",
"CODCOM", "COMUNE", "PROCOM", "NSEZ",
]
census.drop(dropped_columns, axis="columns", inplace=True)
# Compute census cella area
census.loc[:, "geom_area"] = census.area
# Put columns name in lower case
census.columns = census.columns.str.lower()
# Compute target density percentage
census.loc[:, "density_percentage"] = census["target"] / census["geom_area"]
print("- Make Geodataframe with requested census data | DONE ...")
if output_data_folder is None:
return census
else:
file_name = f'census_{year}.gpkg'
census.to_file(output_data_folder / file_name, driver='GPKG', layer='census')
print("- GeoDataFrame with requested census data saved as %s in %s", file_name, output_data_folder)
La funzione __census_geodata non fa nient'altro che prendere tutti gli shp delle celle censuarie e metterli in un unico GeoDataframe.
