
Lavorando sui dati di OSM mi sono trovato a dover affrontare un piccolo grande problema di sovrapposizione di vettori lineari.
Ho scaricato una grossa mole di dati relativi all'idrografia della Francia orientale usando il plugin QuickOSM e, siccome l'area era davvero vasta, l'ho dovuta suddividere in quadranti di 100km di lato. Solo in questo modo, sfruttando ogni singolo quadrante, ho potuto effettuare il download in maniera corretta e senza superare il tempo massimo di risposta del server.
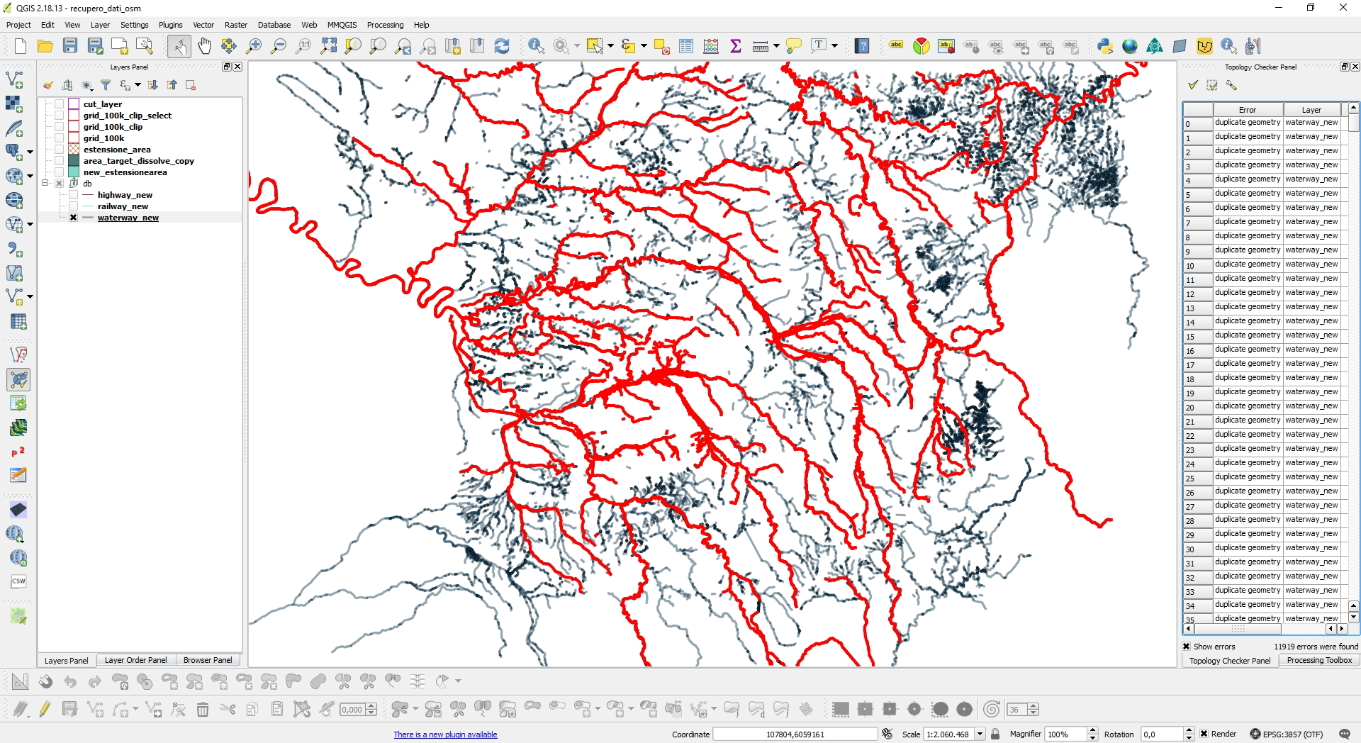
Questa procedura ha però fatto nascere la problematica che mi ha portato a fare questo articolo ed il video tutorial che troverai in fondo. In pratica, ogni qualvolta scaricavo da un quadrante l'idrografia ed esso era attraversato da fiumi che a loro volta attraversavano altri quadranti, questi venivano caricati anche nel quadrante attivo in quel momenti e, visto che tutto confluiva in un unico vettore lineare presente in un GeoDB contenuto in PostGIS, mi sono ritrovato tantissimi duplicati; nello specifico 11.919! I duplicati oltre a rendere il vettore pesante lo rendevano affetto da errori topologici.
Mi sono accorto di questi duplicati perchè ho fatto una verifica topologica con il plugin Topology Checker impostando la verifica sui duplicati, così come visualizzato nell'immagine che segue.

Effettuata la verifica il risultato è stato quello che vedi di seguito.
Indagando la tabella attributi ho notato la presenza della colonna full_id e, guardando il feature ID delle geometrie duplicate presenti nel report di Topology Checker, ho notato che in quella colonna i duplicati erano facilmente individuabili perchè avevano lo stesso full_id.
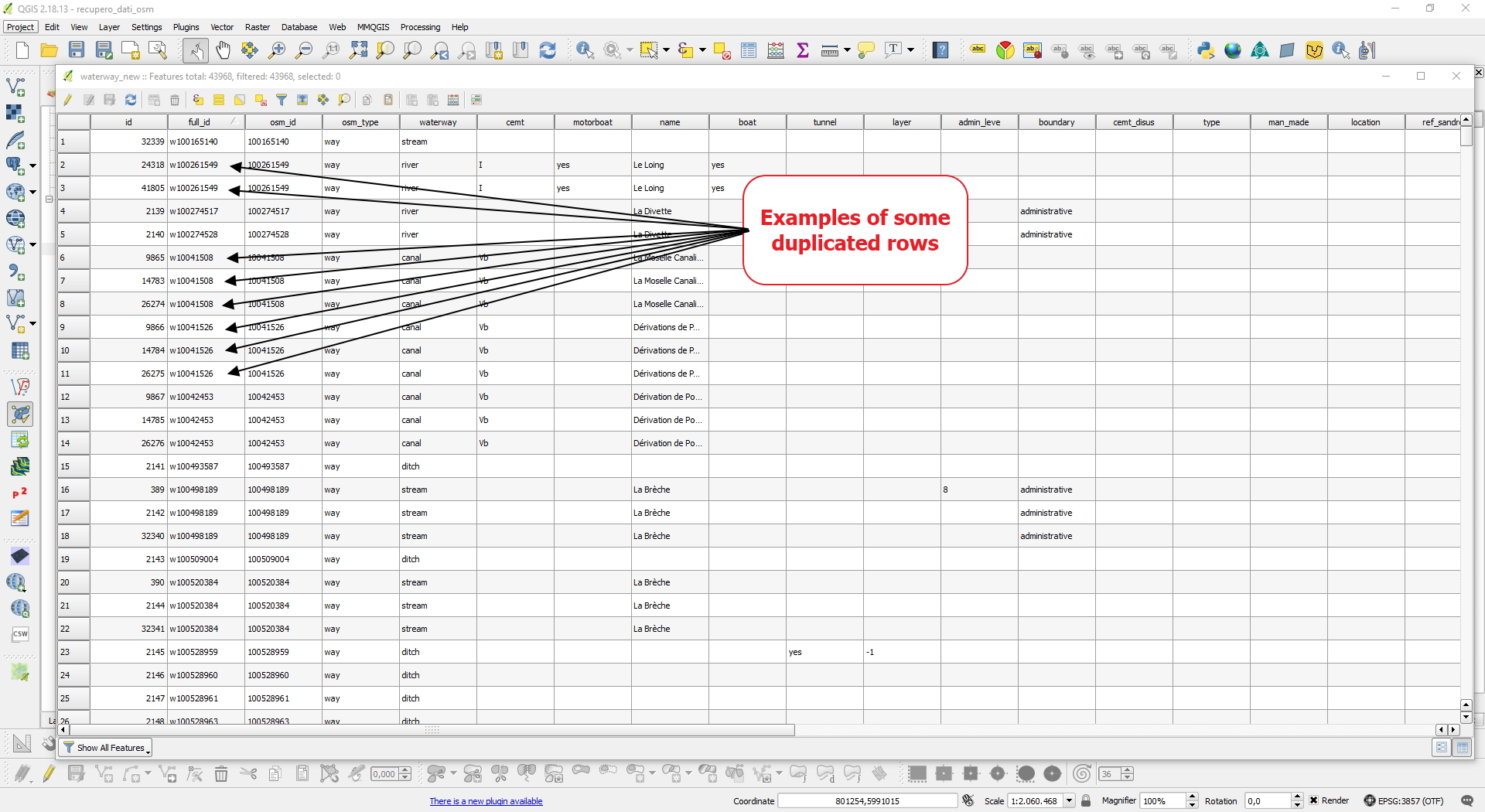
Istintivamente mi sono così concentrato su quella colonna e visto che volevo risolvere il tutto usando l'SQL mi sono documentato in giro sul web su come poter eliminare il problema.
Ho prima lanciato questa query:
SELECT
full_id,
COUNT(full_id) AS counter
FROM waterway_new
GROUP BY full_id
ORDER BY counter;
Individuando così un elenco di duplicati. Alcuni fiumi erano duplicati anche 7 volte!
Poi ho usato la query che segue per creare un nuovo vettore depurato dai duplicati:
CREATE TABLE waterway_new_noduplicate AS
SELECT DISTINCT ON (full_id) *
FROM waterway_new;
Tutta la procedura l'ho racchiusa nel video tutorial che trovi di seguito. Un'altra strada sarebbe potuta essere quella di usare il plugin MMQGIS senza quindi usare l'SQL.
